Support teams usually do not have a ticket volume problem only.
They have a review coverage problem.
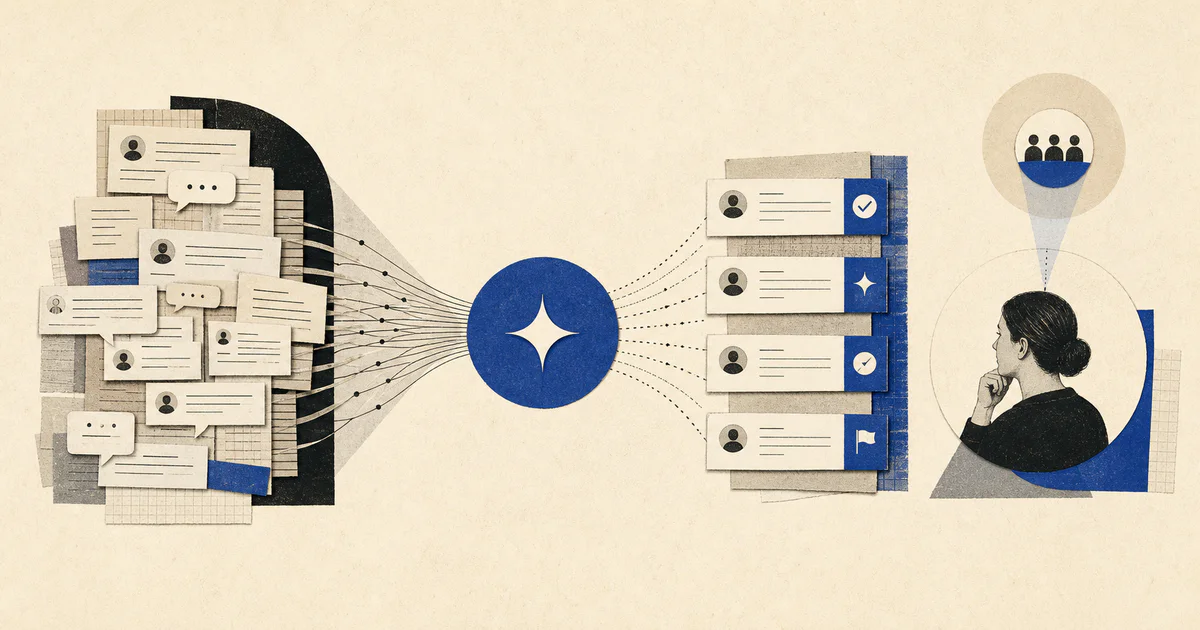
A QA lead may want to inspect whether agents followed policy, used the right tone, handled refunds correctly, escalated technical issues on time, and documented the case clearly. But once the queue gets large, most teams review a small sample and hope it represents the whole operation. That leaves too many missed coaching issues, too many scoring arguments, and too little visibility into where support quality is actually slipping.
That is the real problem AI support QA automation solves.
Short answer: AI support QA automation reviews support conversations against defined quality rules, flags likely misses, explains why the ticket was flagged, and sends the right cases to a human reviewer so teams can inspect more work without trusting blind automation.
If your bigger issue starts before QA, look at AI support triage systems, AI support ticket routing automation, and AI support escalation automation. QA automation sits downstream of those workflows and helps leaders verify that the support system is actually producing better outcomes.